Abstract
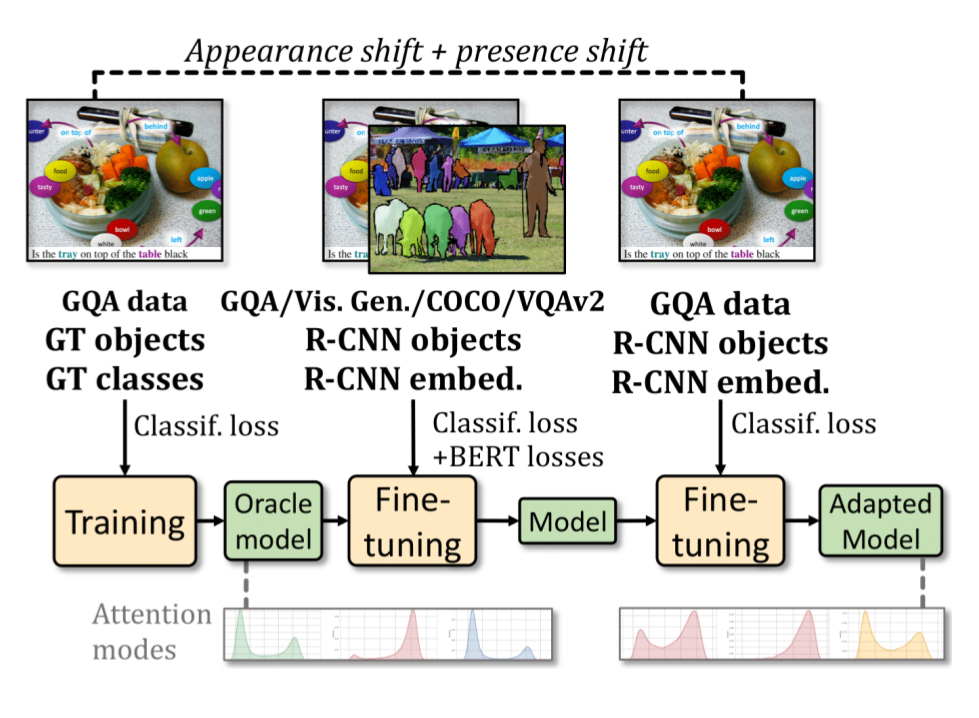
Since its inception, Visual Question Answering (VQA) is notoriously known as a task, where models are prone to exploit biases in datasets to find shortcuts instead of performing high-level reasoning, required for generalization. Classical methods address these issues with different techniques including removing biases from training data, or adding branches to models to detect and remove biases. In this paper, we argue that uncertainty in vision is a dominating factor preventing the successful learning of reasoning in vision and language problems. We train a visual oracle with perfect sight, and in a large scale study provide experimental evidence that it is much less prone to exploiting spurious dataset biases compared to standard models. In particular, we propose to study the attention mechanisms at work in the visual oracle and compare them with a SOTA Transformer-based model. We provide an in-depth analysis and visualizations of reasoning patterns obtained with an online visualization tool which we make publicly available https://reasoningpatterns.github.io. We exploit these insights by transferring reasoning patterns from the oracle model to a SOTA Transformer-based VQA model taking as input standard noisy inputs. Experiments show successful transfer as evidenced by higher overall accuracy, as well as accuracy on infrequent answers for each type of question, which provides evidence for improved generalization and a decrease of the dependency on dataset biases.
@inproceedings{Kervadec2021transferable,author = {Kervadec, Corentin and Jaunet, Theo and Antipov, Grigory and Baccouche, Moez and Vuillemot, Romain and Wolf, Christian},
title = {How Transferable are Reasoning Patterns in VQA?},
journal = {IEEE Conference on Computer Vision and Pattern Recognition},
year = {2021},
}